
Warehouse Wisdom. Lakehouse Speed.
We fuse classic modelling with cloud-native muscle, so your data moves at lakehouse speed.
Proven Modelling Patterns—Re-imagined for Today
Choosing a “one-size-fits-all” model is outdated. We blend these patterns to match your data sources, governance needs, and growth plans.
Approach
Core Idea
When It Shines Now
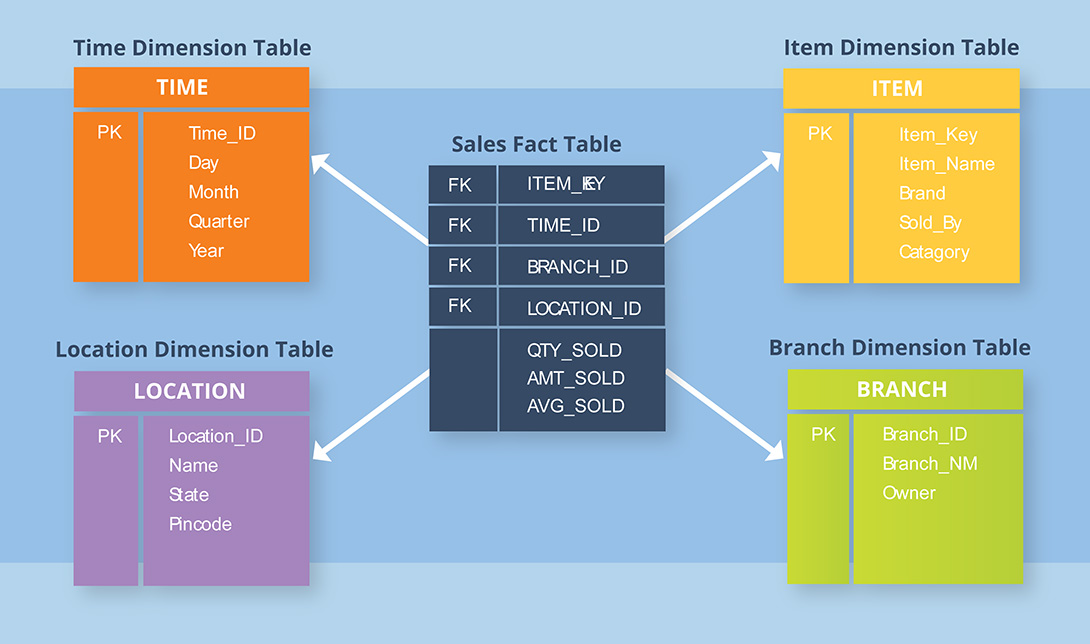
Kimball Dimensional / Star Schema
Denormalised facts & dimensions for fast BI.
Interactive Power BI & Fabric dashboards, where query speed and user-friendly models matter.
Corporate Information Factory
Normalised enterprise warehouse feeding subject-area marts.
Regulated industries that need a single version of the truth before data is re-shaped for analytics.
Hybrid Kimball + Inmon
CIF core for governance, star-schema marts for speed.
Large enterprises balancing auditability with self-service BI.
Data Vault 2.0
Hubs, Links, Satellites for agility & historisation.
Cloud lakehouses where schema drift is common and automated CI/CD is key.
BEAM✲ Analysis
Business-event-centred requirements gathering.
Agile projects that iterate directly with business users to avoid model mis-fit.
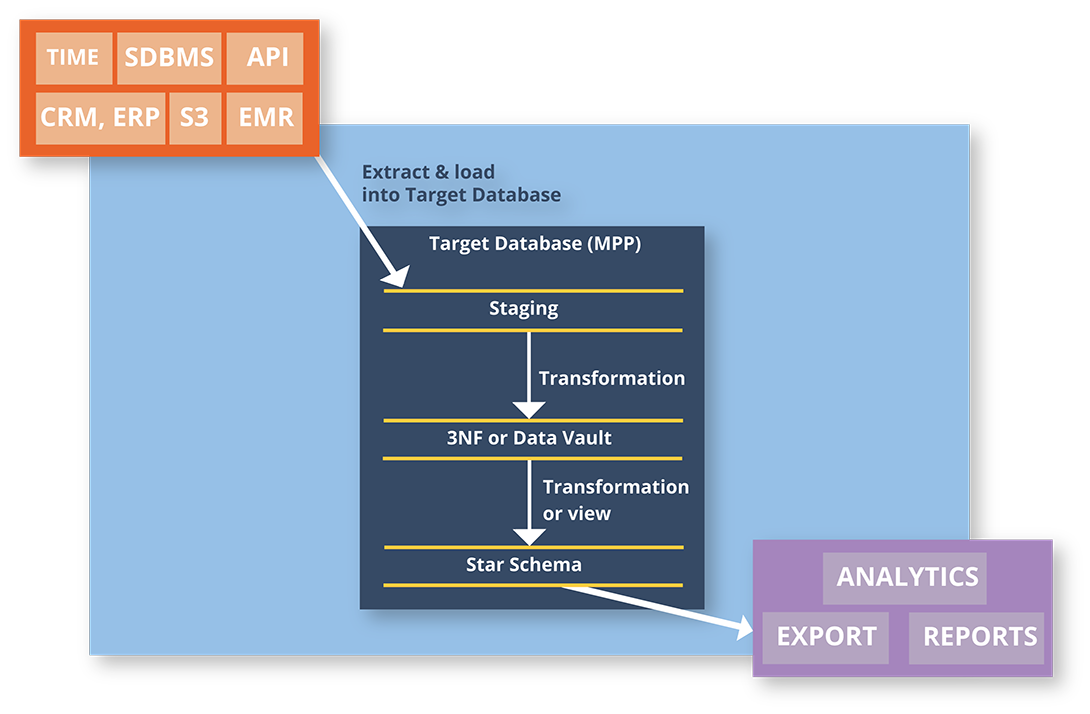
Modern Data Warehousing on Azure
Unify, Transform, and Accelerate Insight—Without Compromising Performance.
Modern data warehousing brings all your enterprise data—structured and unstructured—together on a scalable, secure platform powered by Azure Data Factory, Azure Synapse, and the Lakehouse architecture.
Whether you’re integrating sales, operations, or customer data from across your ecosystem, a modern warehouse enables:
- Seamless ETL/ELT pipelines with Data Factory and metadata-driven patterns
- Centralized storage using the medallion architecture (Bronze, Silver, Gold) in OneLake or Delta Lake
- Decoupled compute for reporting and analytics using tools like Power BI, without touching production systems
- Enterprise-grade scalability and governance using Microsoft Purview and Azure-native controls
With a future-ready data platform, you enable self-service analytics, support real-time insight, and lay the foundation for AI—without compromising the performance of your source systems.
Core Data Warehouse Architectures
All data warehouse designs stem from three foundational architectures—everything else is just a variation on these proven blueprints.
Kimball – Datamart
Modern data warehousing brings all your enterprise data—structured and unstructured—together on a scalable, secure platform powered by Azure Data Factory, Azure Synapse, and the Lakehouse architecture.
Whether you’re integrating sales, operations, or customer data from across your ecosystem, a modern warehouse enables:
- Seamless ETL/ELT pipelines with Data Factory and metadata-driven patterns
- Centralized storage using the medallion architecture (Bronze, Silver, Gold) in OneLake or Delta Lake
- Decoupled compute for reporting and analytics using tools like Power BI, without touching production systems
- Enterprise-grade scalability and governance using Microsoft Purview and Azure-native controls
With a future-ready data platform, you enable self-service analytics, support real-time insight, and lay the foundation for AI—without compromising the performance of your source systems.
Corporate Information Factory
Often called the father of the data warehouse, Bill Inmon laid the foundation for enterprise data architecture. He defined a data warehouse as:
“A subject-oriented, integrated, time-variant, and non-volatile collection of data in support of management decision-making.”
Inmon’s top-down approach begins with a centralized, normalized enterprise data warehouse (EDW) that serves as the single source of truth. All source systems feed into the EDW through robust ETL pipelines. From there, downstream systems—such as reporting tools and data marts—consume cleansed, governed data.
The key advantage? Decoupling. If a source system changes, only the ETL layer needs to adapt—leaving analytics, dashboards, and reports untouched. This creates a strong separation between operational and analytical systems, especially valuable when integrating third-party or external data.
Inmon’s architecture is ideal for organizations that prioritize data quality, governance, and stability across complex enterprise ecosystems.
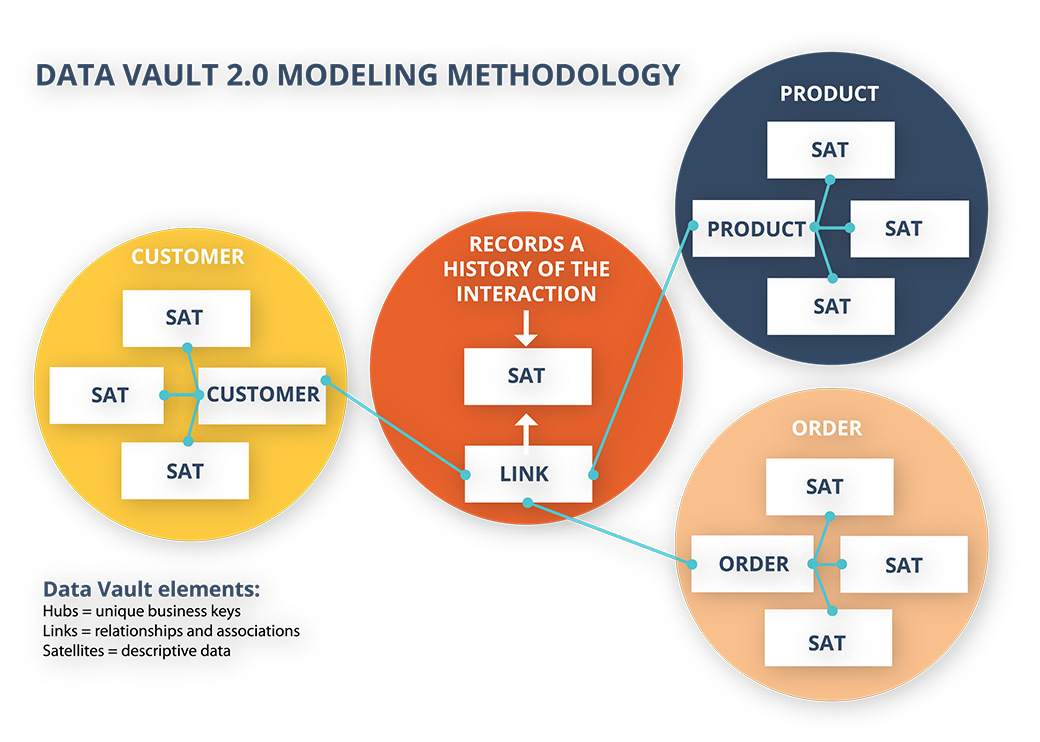
Data Vault 2.0
Data Vault 2.0 is a modern evolution of enterprise data architecture, offering an alternative to both Kimball and Inmon. Created by Dan Linstedt, it was designed to address the growing demands of agility, traceability, and scalability in today’s data environments.
At its core, Data Vault separates business keys (Hubs), relationships (Links), and contextual data (Satellites)—creating a structure that is highly adaptable, auditable, and built for long-term historical storage.
Why choose Data Vault?
- Built-in auditability for compliance-heavy industries
- End-to-end data lineage and traceability
- Faster parallel loading of data from multiple sources
- Resilient to source system changes without breaking downstream processes
Data Vault 2.0 is particularly effective in complex, fast-changing environments—where agility, data governance, and consistency are non-negotiable.
“All the Data, All the Time”
Unlike traditional data warehouse models that strive for a single version of the truth—often by cleansing or excluding non-conforming data—Data Vault 2.0 stores “a single version of the facts.” As creator Dan Linstedt puts it:
“All the data, all of the time.”
This approach preserves the raw, unfiltered data—ensuring full auditability and traceability—while allowing business rules to be applied flexibly downstream.
Designed for modern data demands, Data Vault 2.0 supports highly parallelized loading, making it ideal for Big Data environments. Its architecture naturally scales both up and out, accommodating a mix of streaming, structured, and unstructured data without constant redesign.
If your organization handles massive, fast-changing data from diverse sources—and you need to keep performance, lineage, and agility intact—Data Vault 2.0 is built for you.
Data Lakes
Store everything. Analyze anything. Scale effortlessly.
Why Data Lakes
A Data Lake is a central repository that stores all your enterprise data in its raw, native format—whether structured, semi-structured, or unstructured. From database records and CSV files to IoT feeds, PDFs, images, and video—it all belongs in the lake.
Typically deployed in the cloud (e.g., Azure Data Lake Storage), data lakes are designed to handle massive volumes of diverse data types that traditional warehouses struggle to support.
Key benefits of a data lake include:
- Cost-effective scalability for Big Data
- Flexible storage of disparate sources with no upfront schema
- Ideal for advanced analytics, AI/ML, and data science workloads
However, storing raw files and blobs can lead to metadata loss—such as data types, business rules, and validation logic—if not managed properly. That’s why modern data platforms pair Data Lakes with governance tools (e.g., Microsoft Purview) and Lakehouse architectures to add structure, lineage, and usability.
For complex organizations dealing with diverse and disconnected data sources, a data lake is the foundation of a future-ready, insight-driven enterprise.
However, storing raw files and blobs can lead to metadata loss—such as data types, business rules, and validation logic—if not managed properly. That’s why modern data platforms pair Data Lakes with governance tools (e.g., Microsoft Purview) and Lakehouse architectures to add structure, lineage, and usability.
For complex organizations dealing with diverse and disconnected data sources, a data lake is the foundation of a future-ready, insight-driven enterprise.
How do Data Lakes work?
Think of a data lake like a real lake—data flows in from various sources, fills the reservoir (storage), and flows out when needed for analysis, reporting, or machine learning.
Data is ingested in its raw format from a wide range of systems—databases, APIs, logs, IoT devices, files, and more. Unlike traditional data warehouses, lakes don’t enforce a schema on write. Instead, schema is applied on read, giving you flexibility and speed in handling diverse datasets.
Data lakes support:
- Batch and streaming ingestion
- Storage of structured, semi-structured, and unstructured data
- Scalable analytics using distributed processing tools like Apache Spark
What Is Delta Lake?
Delta Lake is an open-source storage layer that sits on top of your existing Data Lake (e.g., Azure Data Lake Storage) and brings reliability and performance enhancements to big data workloads.
With Delta Lake, you get:
- ACID transactions for data reliability
- Time travel and data versioning
- Faster reads and writes through indexing and caching
- Schema enforcement and evolution
- Seamless integration with Apache Spark and Databricks
